Fundamentals of Machine Learning
7. Deep Learning Part 2
In Deep Learning Part 1, we introduced deep learning and the fundamentals of neural networks. In this article, we will learn more about how neural networks work.
In a neural network, data is passed from layer to layer in several steps.
- Input is multiplied by corresponding weights
- Weighted inputs are summed
- The sum is converted to another value using a math transformation (activation function)
There are several functions that can be applied in step 3.
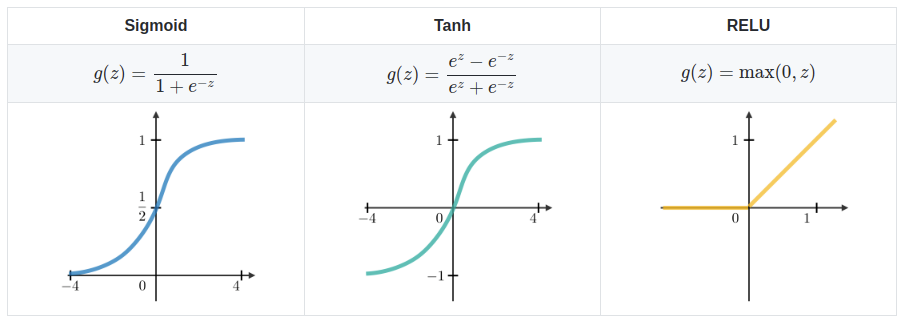
Activation Functions
Activation functions define how a weighted sum of the input is transformed into an output from a node. Think of it as an additional transformation performed on the data. Below are three main examples of activation functions: Sigmoid, Tanh, and ReLU.
Forward Propagation (Forward Pass)
Now, let’s discuss how the neural network passes information from the input layer to the hidden layers until the output layer.
At each layer, the data is transformed in three steps.
- The weighted input (input X weight) is summed
- An activation function is applied to this sum
- The result is passed to the neurons in the next layer
When the output layer is reached, the final prediction of the neural network is made. This entire process is called Forward Propagation (Forward Pass).

Loss/Cost Functions
After the forward pass is run on the network, we want some say to test how well the model is doing. To do this, we can use a loss function, a function that calculates the error of a model. Loss is defined as the difference between the model’s predicted output and the actual output. A common loss function is mean squared error (MSE). Our goal is to minimize the loss, leading us to the next topic.

In Deep Learning Part 3, we will learn how networks learn from experience.